python 英数字のPDF内のテキストを取得する

pythonで、英数字のPDF内のテキストを取得するサンプルコードを記述してます。pythonのバージョンは3.9.7を使用してます。
環境
- OS Ubuntu 21.10
- python 3.9.7
PyPDF2インストール
まずはライブラリ「PyPDF2」を、pipでインストールしておきます。
pip3 install PyPDF2
<出力結果>
Collecting PyPDF2
Downloading PyPDF2-1.26.0.tar.gz (77 kB)
|████████████████████████████████| 77 kB 6.4 MB/s
Building wheels for collected packages: PyPDF2
Building wheel for PyPDF2 (setup.py) ... done
Created wheel for PyPDF2: filename=PyPDF2-1.26.0-py3-none-any.whl size=61084 sha256=9353dba200c3d960b84be1487f20f3e47322b4eafc2609c925805b1ef318f637
Stored in directory: /home/testuser/.cache/pip/wheels/d9/dc/ec/72da68331f30074b9950c1737c23cb8a67484e61498bc9713d
Successfully built PyPDF2
Installing collected packages: PyPDF2
Successfully installed PyPDF2-1.26.0サンプルコード
適当なPDFをダウンロードします。自分はここのサイトからダウンロードしてます。
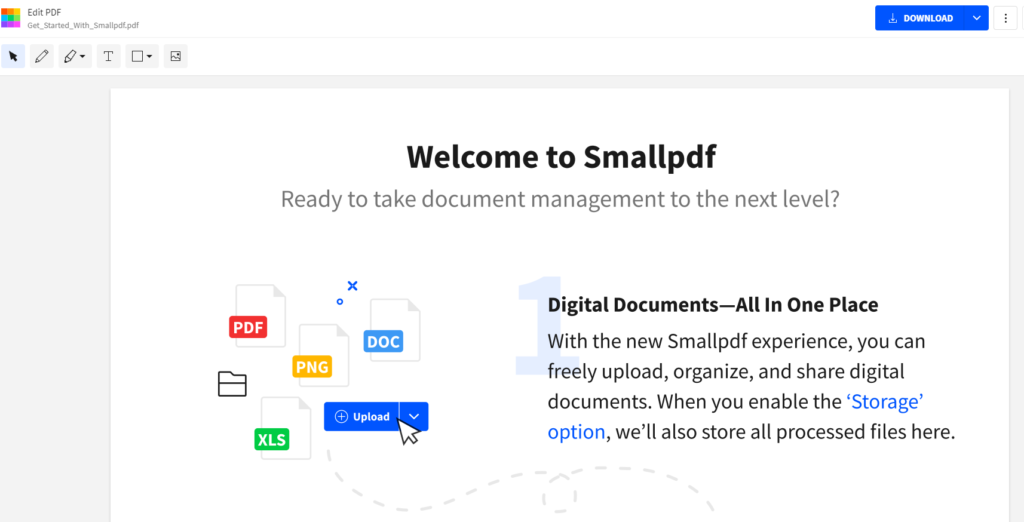
PyPDF2を使用して、テキストデータを取得して出力します。
※ここでは「pdf.py」というファイル名にしてます。
import PyPDF2
with open("Get_Started_With_Smallpdf.pdf", "rb") as f:
r = PyPDF2.PdfFileReader(f)
page = r.getPage(0)
print(page.extractText())実行してみます。
python3 pdf.py実行結果
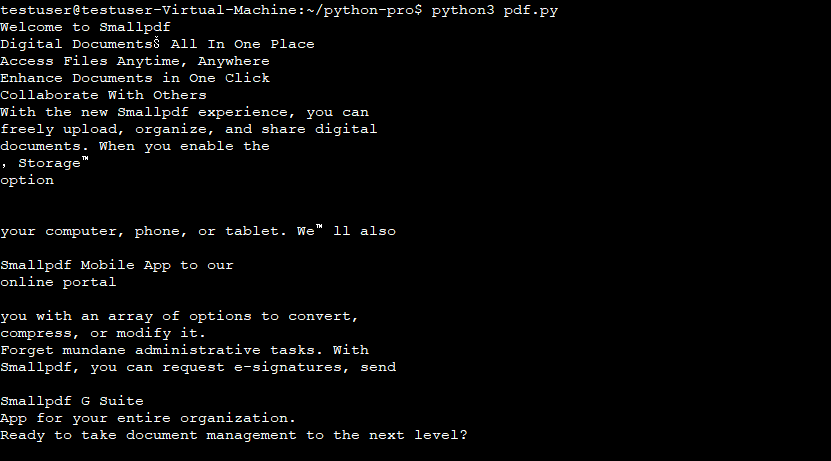
テキストデータが取得されていることが確認できます。
-
前の記事

VSCODE ASP.NET Core Npgsqlを使用する 2021.10.29
-
次の記事
TablePlusを使ってredisに接続する 2021.10.29