PostgreSQL エスケープされたUnicode文字を文字列に変換する
- 作成日 2023.01.01
- 更新日 2023.01.02
- PostgreSQL
- PostgreSQL

PostgreSQLで、エスケープされたUnicode文字を文字列に変換する手順を記述してます。「unistr」にUnicode文字を指定することで可能です。実行結果はpgadmin上で確認してます。
環境
- OS CentOS Stream release 9
- PostgreSQL 15.1
- pgadmin4 6.16
手順
指定した区切り文字で配列を作成するには、「string_to_array」を使用します。
unistr(Unicode文字);
指定できる形式は以下となります
\XXXX(16進数4桁)
\+XXXXXX(16進数6桁)
\uXXXX(16進数4桁)
\UXXXXXXXX(16進数8桁)実際に、判定してみます。
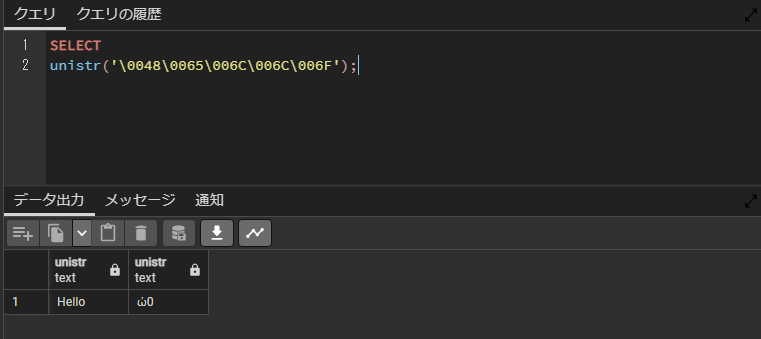
SELECT
unistr('\0048\0065\006C\006C\006F');実行結果を見ると、変換されていることが確認できます。
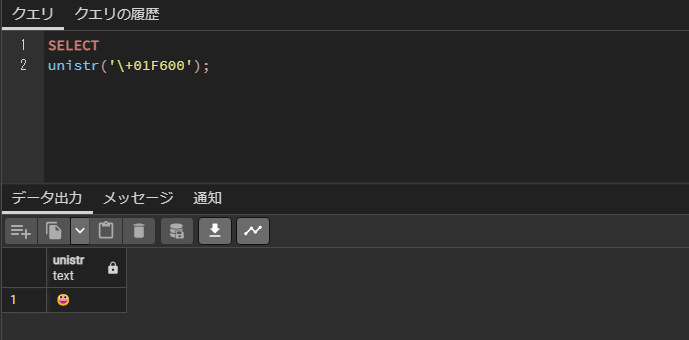
サロゲートペア
サロゲートペア文字のような通常の2バイトで1文字で表すところを、4バイトで1文字となるものでも、変換可能です。
SELECT
unistr('\+01F600');実行結果
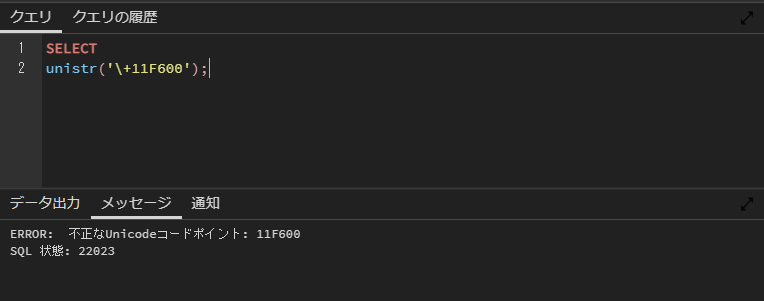
存在しない値
存在しない値を指定するとエラーとなります。
SELECT
unistr('\+11F600');
ERROR: 不正なUnicodeコードポイント: 11F600
SQL 状態: 22023実行結果
-
前の記事

javascript エラー「Uncaught TypeError: xxxxx.get is not a function」の解決方法 2023.01.01
-
次の記事

C# WPF Gridを使用する 2023.01.01